現在,請大家一起數一下“1”、“2”。
OK,短短2秒鐘時間,一個準萬億MoE大模型就已經吃透如何解一道高等數學大題了!
而且啊,這個大模型還是不用GPU來訓練,全流程都是大寫的“國產”的那種。

這,就是華為通過“昇騰 Pangu Ultra MoE”這套組合拳解鎖的效果——
不僅實現了國產算力與國產模型全流程自主可控的訓練閉環,更是在集群訓練系統性能方面達到行業領先水平。
有多領先?來看一組數據:
預訓練階段:昇騰Atlas 800T A2萬卡集群MFU提升至41%
后訓練階段:單CloudMatrix 384超節點吞吐達35K Tokens/s
值得一提的是,華為還首次把背后的一大秘籍給亮了出來。
具體來說,華為在這次發布的技術報告中,披露了在昇騰CloudMatrix 384超節點上,高效打通大稀疏比MoE強化學習后訓練框架的關鍵技術。
此舉可以說是讓以強化學習(RL)為核心機制的后訓練,進入到了超節點集群時代。
不用GPU的“煉”出準萬億大模型方法
在深入華為Pangu Ultra MoE訓練系統全流程之前,老規矩,我們還是先來了解一下此前的技術痛點。
整體來看,在當前的MoE預訓練和強化學習后訓練過程中所存在的挑戰可以歸結為六點:
并行策略配置困難
面對數據并行、張量并行、專家并行、流水線并行和序列并行等多種策略的組合選擇,加上稀疏激活導致的負載不平衡因素,很難通過人工經驗找到最優的并行配置方案。
All-to-All通信瓶頸
專家并行架構需要進行大規模的token路由交換,這不僅占用大量網絡帶寬資源,還會造成計算資源長時間空閑等待,嚴重影響整體訓練效率。
系統負載分布不均
從注意力機制中序列長度的差異,到專家激活頻率的不平衡,再到流水線并行中各階段的負載分配問題,這些多層次的不均衡現象拖累了整個集群的性能表現。
算子調度開銷過大
動態路由機制引入了大量高頻率的小規模算子操作,增加了系統調度負擔,降低了核心矩陣計算的比重,從而顯著影響NPU的有效利用率。
訓練流程管理復雜
強化學習后訓練涉及多個模型實例和多種訓練任務,包括MoE大模型的訓練和推理階段,整個流程的復雜性給資源分配和系統調度帶來巨大挑戰。
大規模擴展受限
強化學習過程中,訓練與推理階段的參數重新映射機制,以及各計算任務間復雜的數據通信流程,成為制約后訓練大規模部署的主要瓶頸。
即使挑戰如此之多,華為在這段技術報告中依舊是給出了一套完整的端到端全流程解法。
第一招:提升訓練集群利用率
超大規模訓練集群的高效部署是提升預訓練系統性能的關鍵所在。
為此,華為團隊通過并行策略智能選擇、計算通信深度融合、全局動態負載平衡等技術創新,顯著提升了集群整體訓練效率。
首先是建模仿真驅動的智能并行優化。
華為團隊采用如下圖所示的系統建模仿真框架,將原本需要大量人工試錯的并行策略選擇問題轉化為精確的自動化搜索過程。
基于昇騰800T A2訓練集群的硬件特性和約束條件,為Pangu Ultra MoE 718B模型確定了最優部署配置:
16路流水線并行(Pipeline Parallelism)進行模型層間切分8路張量并行(Tensor Parallelism)專門處理注意力計算32路專家并行(Expert Parallelism)實現專家模塊分布式計算2路虛擬流水線并行(Virtual Pipeline Parallelism)提升流水線效率
最終實現了與昇騰架構深度適配的最優化部署方案。
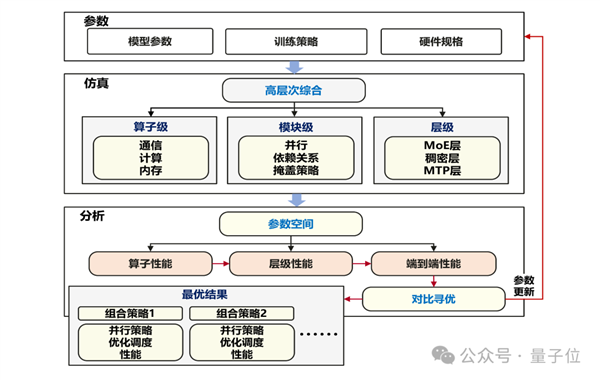
△訓練系統建模仿真流程
其次是Adaptive Pipe前反向通算掩蓋。
為了突破并行擴展中的通信瓶頸問題,華為團隊創新設計了昇騰網絡拓撲適配的分層All-to-All通信去冗余機制,結合細粒度前反向計算重疊編排,成功將大規模MoE訓練中的專家并行通信開銷降至接近零暴露(<2%):
層次化專家并行通信:華為給出了與昇騰訓練集群拓撲深度適配的多級通信策略。首先在節點間進行去冗余的token收集操作,避免相同token在低帶寬的跨節點鏈路上重復傳輸;隨后利用節點內高帶寬優勢,通過All-to-All通信實現token的冗余分發。這一分層設計顯著提升了專家并行的整體通信效率。
自適應細粒度前反向掩蓋:針對分層專家并行通信特點,設計了基于虛擬流水線并行(VPP)的細粒度前反向重疊掩蓋策略。相比業界DualPipe掩蓋方案,該策略將權重內存占用減少一半。通過進一步拆解MLP模塊計算流程,充分利用分層專家并行通信中各級帶寬相對獨立的特性,實現算子執行順序的自適應調優,最終將專家并行通信幾乎完全隱藏(未掩蓋比例僅為2%)。
最后是EDP Balance 全局動態負載均衡。
對于MoE模型,模型規模和集群規模的增長會導致專家計算、注意力計算以及各層間的負載不均衡問題相互疊加并被顯著放大。當多種性能瓶頸同時出現時,通信同步等待會在系統中傳播擴散,造成整體性能的嚴重惡化。
華為團隊采用系統性的分析方法,深入剖析專家并行(EP)、數據并行(DP)、流水線并行(PP)各通信域中潛在的負載均衡挑戰,提出了EDP全局負載均衡優化策略。
這個策略不僅通過專家負載預測和動態調節機制(如下圖)實現設備間計算負載的精確平衡,還通過注意力數據重排技術進一步優化了數據并行域間的負載分布效果。
此外,團隊將虛擬流水線并行(VPP)機制與硬件規格特點相結合,設計了最優混合并行架構,有效緩解了模型各層間計算負載分布不均的問題,大幅提升了整體訓練效率。
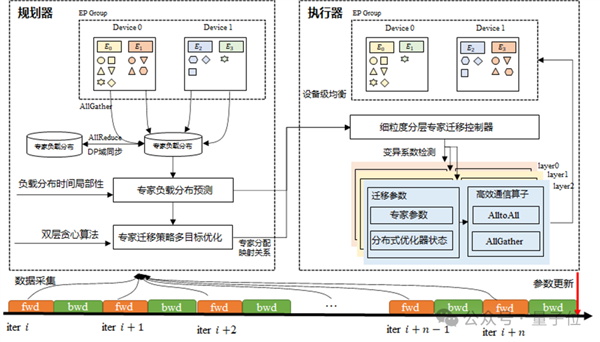
△基于專家動態遷移的EP間負載均衡整體框架圖第二招:釋放昇騰單節點算力
在昇騰超大規模集群優化實現突破性進展后,華為團隊將優化焦點轉向底層算子計算效率的深度挖掘。
這個階段的核心工作圍繞昇騰架構深度適配的訓練算子加速展開,通過緩解Host資源瓶頸以及內存優化策略雙重手段,成功將微批處理規模(MBS)提升至原來的兩倍。
同時團隊還對算子調度下發鏈路進行協同優化,最終實現了昇騰單節點算力的全面釋放。
華為團隊的“第二招”,同樣包含三個細分內容:
首先就是昇騰親和的訓練算子加速。
在大模型訓練計算過程中,FlashAttention、MatMul以及Permute/Unpermute等向量操作算子的執行時間占據了算子總計算耗時的四分之三以上。
針對這些關鍵算子類型,華為團隊充分利用昇騰微架構特性,通過算子流水線排布優化和數學等價冗余計算消除等核心技術手段,實現了訓練算子性能的顯著躍升。
其次是Host-Device協同的算子下發優化。
針對同步型間歇性Host-Bound和系統性持續性Host-Bound問題,華為團隊充分發揮昇騰 鯤鵬異構系統協同優勢,構建了分層優化體系來實現高效算子調度:
對于同步型Host-Bound問題,不僅有效消除了同步操作引發的Host資源瓶頸,在無法完全規避同步的場景下,還通過優化鯤鵬處理器的算子下發與調度策略,顯著降低了同步后的Host-Bound開銷。
對于系統性Host-Bound問題,則采用增大微批處理規模(MBS)、鯤鵬CPU NUMA親和性優化等多維度協同手段,大幅提升算子下發效率。
通過算法與系統的深度協同優化,華為團隊成功將MoE模型訓練中的Host-Bound占比控制在2%以下,為超大規模模型訓練探索出了全新的技術范式。
最后是Selective R/S-精準的內存手術方案。
華為團隊構建了一個精密的內存優化框架:以豐富多樣的通用化重計算策略和Swap機制作為“精密工具庫”,涵蓋從模塊級到張量級的細粒度優化選項;配合精心設計的自適應內存管理機制作為“智能調度平臺”。
這個框架針對Pangu Ultra MoE 718B模型訓練需求,實現了多維度、定制化的內存資源精確調配。
通過構建最優內存優化策略組合,以精準的資源管理手段最大化釋放內存空間,成功實現了超過70%的激活值內存節省。
即使在微批處理規模(MBS)翻倍帶來的內存壓力挑戰下,這個方案依然為模型的長期穩定訓練提供了可靠保障。
第三招:首次披露高性能可擴展RL后訓練關鍵技術
華為團隊針對強化學習訓練中異構模型和多任務場景導致的資源利用率偏低問題,通過深入的系統分析和創新設計,提出了RL Fusion訓推共卡技術。
這一技術支持訓練推理共卡、全共卡等多種靈活部署模式(如下圖),實現推理階段資源調度的精細化可控管理,支持張量并行(TP)、數據并行(DP)、專家并行(EP)、流水線并行(PP)等多維并行策略的動態無縫切換。
可在秒級時間內完成訓推狀態轉換,最終實現了RL后訓練集群利用率翻倍的顯著提升。
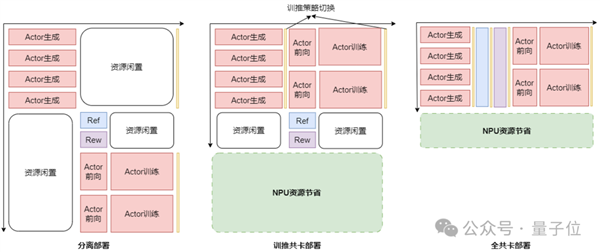
△分離部署、訓推共卡部署、全共卡部署資源利用率示意圖
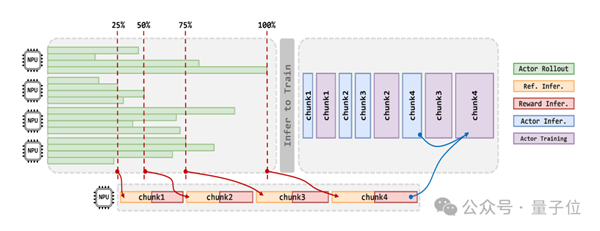
除此之外,華為團隊還展示了面向大規模集群高效可擴展的后訓練框架:
摒棄全同步迭代方式,設計容忍梯度“陳舊性”的準異步機制StaleSync(如下圖),讓不同RL階段的不同任務在“陳舊度閾值”內并行執行。在保證模型精度的前提下,系統整體訓練吞吐提升50%。針對RL階段多任務的處理需求,設計了分布式數據隊列DistQueue,實現不同計算任務之間數據的拆分、緩存與動態讀取。DistQueue對整個后訓練過程中的數據進行管理,有效緩解不同計算任務之間的數據阻塞,為后訓練任務高效調度提供數據支持。
2秒就能讓大模型吃透一道高數大題
通過預訓練和RL后訓練加速技術,華為團隊基于MindSpeed、Megatron以及vLLM框架,打造了昇騰全流程高效訓練系統。
這個系統可支持超大規模集群和超大規模MoE模型,并在Pangu Ultra MoE模型訓練中實現了端到端的流暢訓練。
Pangu Ultra MoE模型擁有7180億參數量,具有大稀疏比和高綜合性能的顯著特點。
其架構包含61層Transformer,前3層為稠密層,后58層為MoE層。模型隱層維度達7680,配備256個路由專家和1個共享專家,專家隱層維度為2048。
在預訓練階段,華為團隊使用6K - 10K卡的昇騰800T A2集群對Pangu Ultra MoE進行訓練。在序列長度為8K、萬卡訓練集群的條件下,模型算力利用率(MFU)創下新高,達到了41%。上述訓練系統具有很強的泛化性,可高效擴展至更大規模參數模型和更大規模卡數集群,同時如果配合昇騰CloudMatrix 384超節點的高速互聯特性,預計可支撐訓練集群MFU > 50%,相關技術迭代實踐結果也將在日后技術報告中發布。
而在RL后訓練階段,于Pangu Ultra MoE昇騰CloudMatrix 384超節點集群的后訓練中,采用訓練推理混合并行策略(訓練:PP16/VPP2/EP32/TP8,推理:PP1/EP64/TP1),并結合異步RL算法與訓練框架系統的協同創新,實現了每超節點35K Tokens/s的高吞吐能力。
同時支持高效擴展超過4K卡的集群,這一效率相當于每2秒就能吃透一道高等數學大題,實現了昇騰超節點吞吐的新突破。
以上便是華為Pangu Ultra MoE訓練系統全流程的深度揭秘了。

鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



