本站5月16日消息,今天騰訊正式發布了業內首個毫秒級響應的實時生圖大模型——混元圖像2.0(Hunyuan Image2.0)。
目前已經在騰訊混元官方網站上線,并對外開放注冊體驗,該模型主要有兩大特點:實時生圖、超寫實畫質。

相比前代模型,騰訊混元圖像2.0模型參數量提升了一個數量級,得益于超高壓縮倍率的圖像編解碼器以及全新擴散架構,其生圖速度顯著快于行業領先模型。
在同類商業產品每張圖推理速度需要5到10秒的情況下,騰訊混元可實現毫秒級響應,支持用戶可以一邊打字或者一邊說話一邊出圖,改變了傳統“抽卡—等待—抽卡”的方式。
除了速度快以外,騰訊混元圖像2.0模型圖像生成質量提升明顯,通過強化學習等算法以及引入大量人類美學知識對齊,生成的圖像可有效避免AIGC圖像中的“AI味”,真實感強、細節豐富、可用性高。
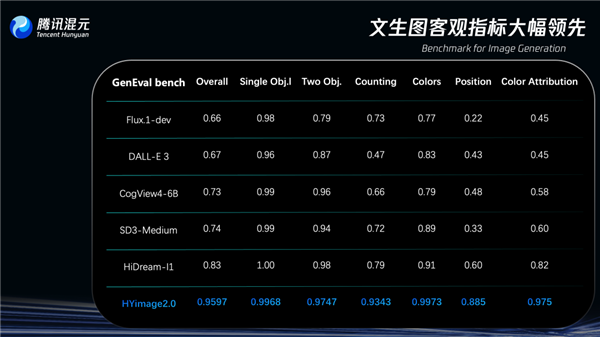
在圖像生成領域專門測試模型復雜文本指令理解與生成能力的評估基準GenEval(Geneval Bench)上,騰訊混元圖像2.0模型準確率超過95%,遠超其他同類模型。

提示詞:人像攝影,愛因斯坦,背景是東方明珠,自拍視角
騰訊表示,騰訊混元圖像2.0引入多模態大語言模型(MLLM)作為文本編碼器,配合自研的結構化caption系統,不僅能理解你在說什么,更能推測出你希望畫面「怎么表達」。
哪怕你一句話里埋了三層含義,它也能一一拆解,再一筆一筆畫出來。

除了文字輸入,騰訊混元圖像2.0還可以通過語音直接輸入提示詞,系統將語音自動轉寫為文字,并在識別后即時生成圖像,適用于直播講解、移動創作等場景。
也可以上傳草圖作為參考,模型能自動識別線稿的結構與構圖邏輯,再結合提示詞內容補全光影、材質、背景等細節,迅速擴展成圖。
騰訊混元圖像2.0模型生成的圖片:

人像攝影風格

動物特寫

復古攝影

動漫風格

真實人物風格
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播更多信息之目的,如作者信息標記有誤,請第一時間聯系我們修改或刪除,多謝。



